ELK-Stack 介紹
嗯,用了許久的 ELK,當然除了使用以外還要會建立
為了免得之後忘記這陣子的研究,來寫寫一系列的紀錄吧
介紹

ELK Stack 是由 Elasticsearch、Logstash、Kibana 以及 Beats 所組成的 Log 蒐集、查詢、分析工具。
1 | # log 資料庫,可以做到全文索引跟搜尋、聚合 log的功能,速度超快 |
可以在不改變原系統架構的情況下,架設 ELK 蒐集、分析、查詢 Log,簡化過去繁鎖、效率差且有可能影響應用程式環境的查 Log 工作。
為何選用 ELK
選擇工具/第三方套件,總要有一些理由/原因,甚至是比較
其實做每件事情都是一樣,事出必有因
- 穩定,官方更新速度快
- 豐富的生態系,不管是
input或output都有很多的第三方可使用 - 官方文件足夠多以及好理解
- 網路資源多/實體資源多(e.g. 書)
- 安裝容易(尤其是利用
docker) - 查詢 log 容易上手
- 只有用過這套(主因或許是這個 XDDDDD)
官方連結
ELK 架構選用
- ELK 使用的版本是
7.6.2 - Redis 使用的版本是
5.0.0
除了 Elasticsearch、Logstash、Kibana 之外,beats 的部分選用了 Filebeat,中介層的緩存以及HA選用 Redis。
中介層的緩存以及 HA 方案也能選用
Kafka
記得要讓 Redis 單獨給 ELK 使用,別跟其他用途混用了!!!
Filebeat
用 Golang 製作,效能很強,用途是爬 log 用的 beat
目前是選擇爬本地端的 Log 檔,然後輸出到 Redis ( 其實他也能獲取很多種套件的 log)
- 詳情請看:Filebeat 設定
Redis
NoSQL資料庫- 讀寫的速度很快
- 可叢集
- 可以當快取使用也能將資料持久化
- 有資料備份機制
- 資料還原發生誤差的機率很低
會選用 Redis 的原因是:
Logstash本身效能並不好Logstash資料備份能力低- 萬一
Logstash掛了,原本暫存在Logstash的 log 會遺失
所以,利用 Redis 的優點,並且當第一層緩衝,減少 Logstash 的壓力
這邊其實也能使用
Filebeat直接將 log 寫到Elasticsearch內,
但要改動較多的程式碼,所以先以比較間單的方式建構
運作方式簡介
各自的詳細運作原理另外再寫,因為篇幅會太長,所以這裡先簡單介紹
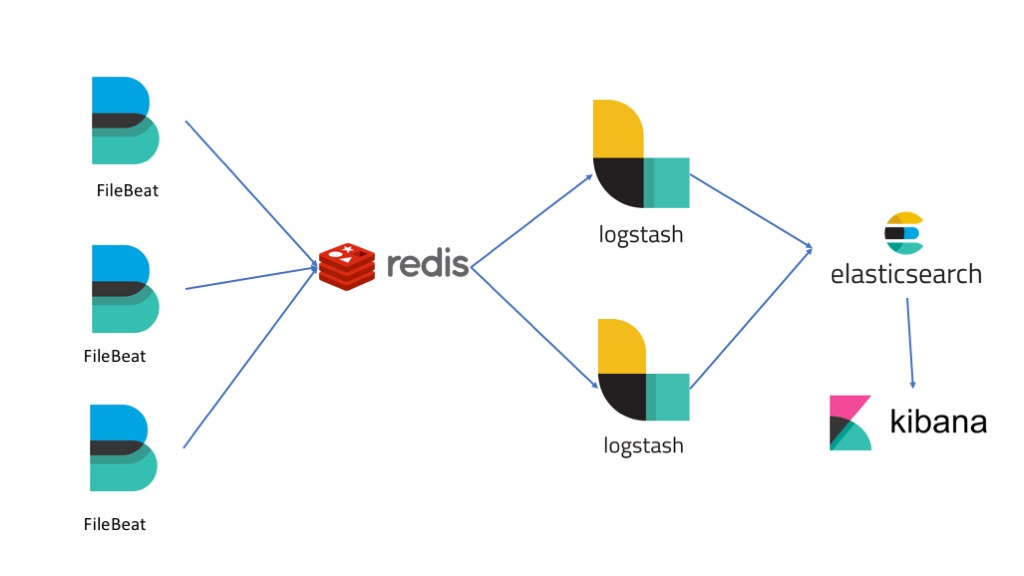
根據上圖
首先是
Filebeat:- 根據設定內的路徑/檔案建立 N個
Harvester,目的是蒐集檔案內的 log - 根據設定內的 output(這裡是使用
Redis),將 log 用RPUSH(預設) 寫入Redis所以不要將
Redis的RPUSH、BLPOP命令更名了
- 根據設定內的路徑/檔案建立 N個
再來是 Redis:
- 要記得做持久化,
aof或rdb或兩者都可,可以根據 log 用途來決定 - 要注意的是,有可能會因為
Logstash獲取 log 的速度慢導致Redis 記憶體持續上升
往下看
Logstash:- 主要區分幾個部分,執行順序由上往下:
inputs:資料輸入來源filter:根據設定來使用內建的工具處理 logoutputs:處理完的資料輸出
inputs(這邊選擇Redis) 透過BLPOP獲取 logfilter根據設定來使用內建的工具處理 log- 處理完成後交給
outputs將處理完的資料輸出(這邊選擇Elasticsearch)
- 主要區分幾個部分,執行順序由上往下:
資料寫到
Elasticsearch後:- 資料寫入索引(
index) - 建立資料對應的
Mapping表 - 根據索引(
index)選擇的文檔(doc)排序方式去排序 - 根據內容建立文檔(
doc)的分數(score),以利快速查詢
- 資料寫入索引(
最後就是
Kibana上場:- 開始查詢啦!
